

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 별찍기
- 인텔리제이 Web 애플리케이션
- System클래스
- StringBuilder
- SQL import
- if else
- 스프링시큐리티 로그아웃
- JAVA 변수
- 중첩 if
- SpringSecurity 로그인
- 스프링부트 로그인
- Scanner 시간구하기
- JSP 실습
- StringBuffer
- 이클립스 설치
- SpringSecurity 로그아웃
- if else if
- Springsecurity
- 증감 연산자
- 접근제어자
- SQL dump
- SpringBoot
- 중첩for
- @PreAuthorize("isAuthenticated()")
- 회원정보 수정
- MySQL workbench dump
- Node.js 설치
- D2Coding
- 클래스 형변환
- jdk 설정
- Today
- Total
gi_dor
RentInsight _ Index 로 조회 성능 올리기 , MySql Profiling으로 병목 구간 측정 본문
RentInsight _ Index 로 조회 성능 올리기 , MySql Profiling으로 병목 구간 측정
기돌 2026. 2. 25. 22:01


EXPLAIN SELECT *
FROM rent_complete
WHERE sgg_cd = '11305' AND umd_nm = '미아동'
AND area BETWEEN 25 AND 36;
- type: ALL
- 데이터베이스가 '풀 테이블 스캔(Full Table Scan)'을 수행
- 의미: rent_complete 테이블의 처음부터 끝까지 모든 데이터를 하나하나 다 뒤져서 조건을 검사하고 있다는 뜻
- possible_keys: <null>, key: <null>
- 이 검색 쿼리를 빠르게 만들어줄 '인덱스(색인)'가 아예 존재하지 않거나 사용되지 않고 있다
- rows: 165,169
- 이 쿼리의 결과를 찾기 위해 DB 엔진이 약 16만 5천 건의 데이터를 읽어야 한다고 `예측` 하고 있다
- filtered: 0.11
- 스캔한 16만 5천 건의 데이터 중, 실제 조건(미아동, 25~36㎡)에 맞는 데이터는 **단 0.11%**에 불과할 것이라고 예측하고 있다
- Extra: Using where
- 스토리지 엔진에서 일단 데이터를 다 끌어올린 다음, MySQL 엔진 단에서 WHERE 조건을 걸어 불필요한 데이터를 버리고 있다는 의미입니다. (비 효율적이란다)
[현재 상태 : 심각한 병목(Bottleneck) 후보]
현재 16만 건 정도의 데이터에서는 0.1초 만에 결과가 나올 수도 있다. 하지만 현재 매일 데이터를 업데이트 하는중인데
전월세 데이터가 쌓여서 100만 건, 1,000만 건이 되면 어떻게 될까?
사용자가 검색 버튼을 딸깍 누를 때마다 DB는 1,000만 건을 다 뒤져야 하고 동시 접속자가 10명만 되어도 데이터베이스 CPU와 메모리가 폭주하여 서비스가 다운(장애)될 수 있는 매우 위험한 쿼리이다.
16만 건을 뒤져서 고작 0.11%의 진짜 데이터를 찾기 위해 99.89%의 헛고생을 하고 있는 상태인것이다
[해결책: 복합 인덱스(Composite Index) 생성] 이 문제를 해결하기 위해 반드시 인덱스(Index)를 만들어주어야 한다.
검색 조건이 sgg_cd = ? (동등 비교), umd_nm = ? (동등 비교), area BETWEEN ? AND ? (범위 검색) 이므로, 동등 비교를 먼저, 범위 검색을 나중에 두는 복합 인덱스를 생성하는 것이 맞다고 판단된다
인덱스 설정 기준
- 쿼리에서 자주 사용되는 컬럼
- WHERE , JOIN , ORDER 등등
- 카디널리티 (값의 분산도 또는 고유성) 수치가 높은 컬럼에 인덱스 설정
sgg_cd시군구 코드 같은경우 서울에 25개 구의 코드가 저장되므로 카더닐리티는 25- 전체 데이터 수에 비하면 변별력이 충분하다고 생각되므로 인덱스 후보로 좋다
umd_nm법정동 이름은 시군구 코드보다 더많으므로 인덱스 후보가된다- 반대로
contract_type계약 종류 같은경우 '신규' , '갱신' 두종류의 값만 있기에 인덱스를 걸면 전체의 절반을 스캔 해야해서 효과가 거의 없을것이다 sgg_cd + umn_nm을 섞은 복합 인덱스를 후보로 보고있다
sgg_cd단독 인덱스 ,sgg_cd + umn_nm복합 인덱스 2개를 만들어서 사용하게 된다면
두개의 인덱스 모두sgg_cd라는 정보를 중복해서 저장하고 있다
종로구 코드 와 종로구 코드 + 숭인동 이라는 정보를 모두 가지고 있으므로
두개의 인덱스 모두 종로구 라는 정보를
두번 저장되므로 디스크 공간을 더 많이 차지하게된다
(sgg_cd, umd_nm) 복합 인덱스 하나만 있어도 MySQL 옵티마이저는 WHERE sgg_cd = '...' 와 같은 쿼리가 들어왔을 때에 복합 인덱스의 첫 번째 부분(sgg_cd)만 사용해서 검색을 효율적으로 수행한다
- 추가로 area 컬럼또한
WHERE .... AND area BETWEEN 53 AND 66으로 사용하기에 선택했다
SELECT
-- 1. 고유 식별자
COUNT(DISTINCT id) AS id_cardinality, -- 거의 전체 행 개수와 동일하게 나옴 (매우 높음)
-- 2. 검색 조건으로 사용될 후보들
COUNT(DISTINCT sgg_cd) AS sgg_cd_cardinality, -- 시군구 코드 (중간 정도)
COUNT(DISTINCT umd_nm) AS umd_nm_cardinality, -- 법정동 이름 (비교적 높음)
COUNT(DISTINCT name) AS name_cardinality, -- 건물 이름
COUNT(DISTINCT area) AS area_cardinality, -- 전용 면적 (매우 높음)
COUNT(DISTINCT build_year) AS build_year_cardinality, -- 건축 년도
-- 3. 범위 검색에 사용될 값들
COUNT(DISTINCT deposit) AS deposit_cardinality, -- 보증금 (매우 높음)
COUNT(DISTINCT monthly_rent) AS monthly_rent_cardinality, -- 월세 (높음)
-- 4. 카테고리성 정보 (카디널리티가 낮을 것으로 예상)
COUNT(DISTINCT contract_type) AS contract_type_cardinality -- 계약 종류 (매우 낮음, 예: '신규', '갱신')
FROM
rent_complete;
CREATE INDEX idx_rent_complete_sgg_umd_area ON rent_complete (sgg_cd, umd_nm, area);
- type: range
- 데이터베이스가 ' 인덱스 범위 스캔 ' 을 수행
- 의미: rent_complete 테이블의 처음부터 끝까지 모든 데이터를 하나하나 다 뒤져서 조건을 검사하고 있다는 뜻
- WHERE 조건으로
- sgg_cd = ? (동등 비교)
- umd_nm = ? (동등 비교)
- area BETWEEN ? AND ? (범위 검색)
- possible_keys, key: idx_rent_complete_sgg_umd_area
- 실제로 만든 복합 인덱스가 사용되고 있다
- 풀테이블 스캔 X
- rows: 43
- 이전에 풀 테이블 스캔 당시 16만 건을 읽어야 했지만 현재 43건만 탐색하면 된
- filtered: 100
- 읽은 데이터 43건이 모두 조건에 만족한다
- 불필요한 데이터가 없다 , 인덱스에서 필터링이 되었
- Extra: Using index condition
- InnoDB 스토리지 엔진 레벨에서 WHERE 조건 일부를 미리 필터링하고 있다
- 인덱스 탐색
- 인덱스에 포함된 컬럼으로 WHERE 조건 검사
- 조건을 통과한 것만 실제 테이블에 접근
- InnoDB 스토리지 엔진 레벨에서 WHERE 조건 일부를 미리 필터링하고 있다
INDEX 미적용
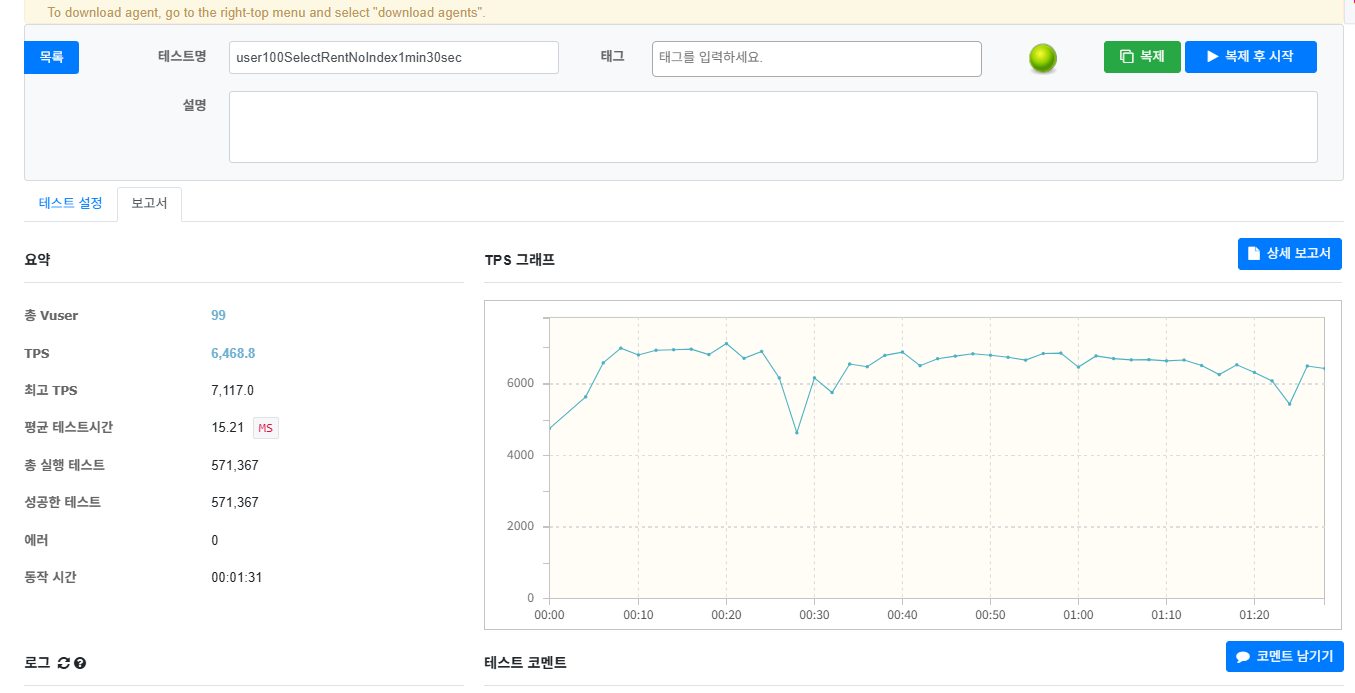
[인덱스 적용 전 성능 지표]
- 평균 TPS (초당 처리량): 6,468.8 req/sec
- 평균 응답 시간: 15.21 ms
- 한계점: 동시 접속자 수가 99명을 초과하면 에러가 발생하며, 시스템이 더 이상 부하를 감당하지 못했음
INDEX 적용
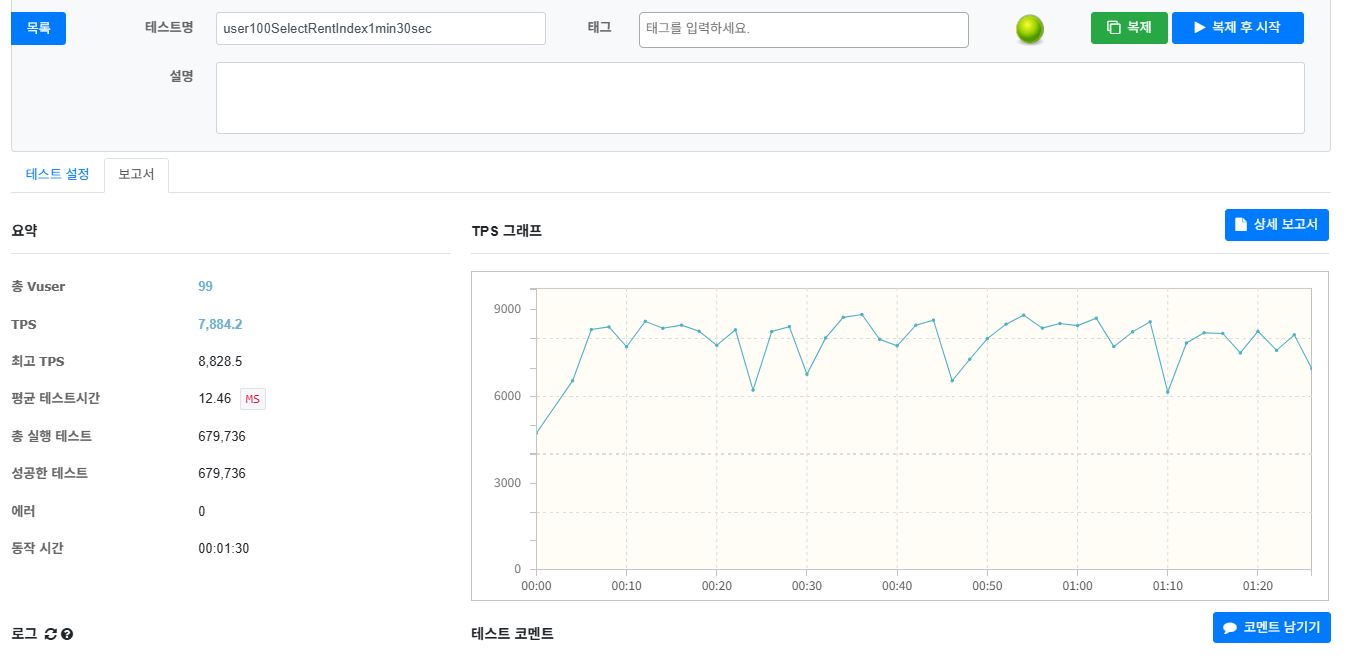
| 인덱스 적용 전 | 인덱스 적용 후 | 개선효과 | |
| 평균 TPS | 6,468.8 | 7,884.2 | +21.9% (초당 1,415건 추가 처리) |
| 최고 TPS | 7,117.0 | 8,828.5 | +24.0% (순간 최대 처리량 증가) |
| 평균 응답시간 | 15.21 m s | 12.46 ms | -18.1% (응답 속도 향상) |
1. 처리 용량 (Throughput) 22% 증가
가장 큰 성과는 평균 TPS가 약 22% 증가한 것이다
동일한 하드웨어 자원으로 같은 시간 동안 22% 더 많은 사용자 요청을 처리할 수 있게 되었음을 의미한다.
풀 테이블 스캔으로 인한 불필요한 I/O 작업이 사라지면서, DB와 서버가 원래의 작업에 더 집중할 수 있게 되었다
2. 사용자 경험
평균 응답 시간이 18% 감소하면서, 사용자는 검색 시 더 빠르고 쾌적한 반응 속도를 체감할수 있을것이다
3. 안정성
99명이 한계였던 시스템이 이제는 더 높은 수인 150명까지 동시 접속을 에러 없이 처리할 수 있게 되었다
데이터가가 더 증가하더라도, 급격한 성능 저하 없이 안정적으로 서비스를 운영할 수 있을것 같다
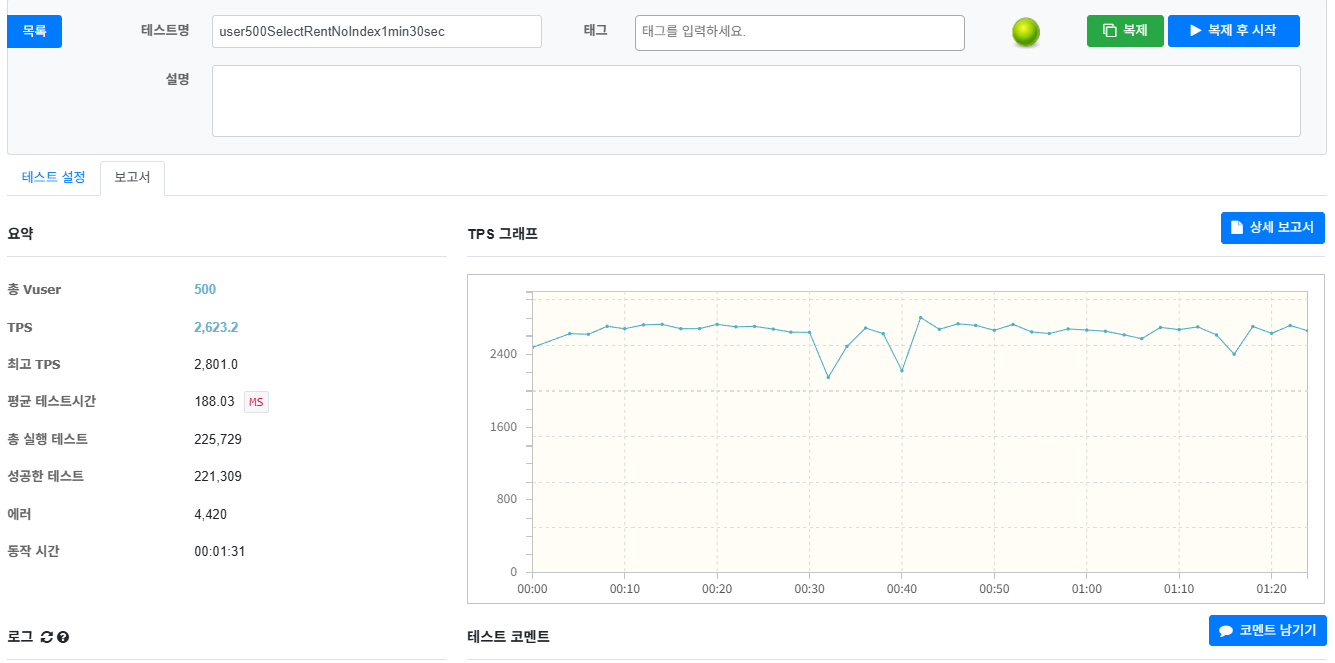
가상 사용자 500명
에러 발생
Mysql Profiling
MySQL 엔진이 쿼리 하나를 실행하는 실제로 각 단계에서 얼마나 시간이 걸리는지 마이크로초 단위로 측정
show variables like '%profiling%';
set profiling=1;
set profiling_history_size=100;
SELECT *
FROM rent_complete
WHERE sgg_cd = '11215'
AND umd_nm = '자양동'
AND area BETWEEN 25 AND 36
order by contract_date DESC;
show profiles; -- id : 18
-- 해당 쿼리문의 수행 시간을 더 상세한 단위로 확인
show profile for query 255;
show profile for query 344;

- 인덱스 적용 전: 0.076037 초 (약 76.0 ms)
- 인덱스 적용 후: 0.001675 초 (약 1.7 ms)
- 절대 시간 감소: 약 74.3 ms의 시간이 단축
- 성능 향상률: (0.076037 - 0.001675) / 0.076037 * 100 ≈ 97.8%
- 결론: 순수한 DB 쿼리 실행 속도가 약 98% 개선, 즉 약 45배 빨라졌다. (76.0 / 1.7 = 44.7058....
1. 저수준(Low-Level) 성능 분석의 필요성
nGrinder를 통한 부하 테스트는 API의 전체 응답 시간과 처리량을 측정하는 데 유용했다
하지만 실제 병목이 발생하는 데이터베이스 내부의 동작을 직접적으로 보여주지는 못한다.
쿼리 성능 개선 효과를 명확하게 증명하기 위해, MySQL의 내장 기능인 Profiling 을 사용하여 순수 SQL 실행 시간을
마이크로초 단위로 측정
2. Profiling을 통한 병목 구간 측정
인덱스 적용 전, WHERE 절에 여러 조건이 포함된 검색 쿼리의 프로파일을 분석한 결과, 총 실행 시간은 약 76ms가 소요
프로파일 상세 내역을 보면 executing 같은 실제 데이터에 접근하여 WHERE 을 필터링하고 , 데이터를 가져오고 , 정렬하는 등
쿼리의 가장 중요한 부분을 수행하는데 시간이 차이 가 많이난다
풀 테이블 스캔(Full Table Scan) 으로 인한 전형적인 성능 저하 패턴이다
3. 인덱스 적용 후 성능 측정
검색 조건에 최적화된 (sgg_cd, umd_nm, area) 복합 인덱스를 생성한 후, 동일한 쿼리에 대해 다시 프로파일링을 실행
45배의 성능 향상 그 의미는?
프로파일링 결과 순수 DB 쿼리 실행 시간이 76ms에서 1.7ms로 단축되어, 약 45배의 폭발적인 성능 향상을 이루었다
nGrinder 테스트에서 TPS가 22% 향상된 것의 근본적인 원인이 바로 이 쿼리 자체의 최적화에 있음을 명확하게 증명한다.
인덱스는 불필요한 디스크 I/O를 제거하고 MySQL이 필요한 데이터에 직접 접근하도록 유도하고 DB 엔진의 부하를 줄였다
이런 최적화는 단순히 단일 쿼리를 빠르게 만드는 것을 넘어 제한된 DB 서버 자원으로 더 많은 동시 요청을 처리할 수 있게 만들어주고 전체 서비스의 처리 용량과 안정성 향상으로 직결된다
'Back_End > SpringBoot' 카테고리의 다른 글
| 다시 돌아온 페이징처리 SpringBoot + MyBatis // Pageable XX (0) | 2026.02.23 |
|---|---|
| [Jackson] API 필드명 @JsonProperty .araboja (1) | 2026.02.21 |
| Spring에서 비동기 @Async (0) | 2024.08.29 |
| [Refactor] 카페인 캐싱으로 성능개선 , Ngrinder (1) | 2024.06.11 |
| 스프링부트 + MyBatis +MYSQL 페이징 처리 (0) | 2024.05.09 |

