
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- @PreAuthorize("isAuthenticated()")
- SpringSecurity 로그아웃
- 자바의정석
- java
- 예약어
- 스프링시큐리티 로그아웃
- 객체지향
- 친절한 SQL
- SQL튜닝
- 객체
- 이클립스 설치
- 친절한 SQL 튜닝
- 인텔리제이 Web 애플리케이션
- 함수
- join
- 반복문
- SQL
- SQL 튜닝
- StringBuffer
- 상속
- 연산자
- 오버로딩
- 비교 연산자
- 논리 연산자
- 산술 연산자
- SpringSecurity 로그인
- spring 게시판 삭제
- 배열
- 오버라이딩
- 식별자
- Today
- Total
gi_dor
🔑 SQL 튜닝 - CH 2. 인덱스 기본 본문
1️⃣ 인덱스 구조 및 탐색
1 - 1 미리보는 인덱스 튜닝
인덱스 특징 : 정렬과 위치
데이터를 찾는 2가지 방법
1 ) Full Scan
2 ) Index Scan
◾ 정렬 데이터
◾ 데이터의 위치
1 - 2 인덱스 튜닝의 두가지 핵심요소
1 ) 인덱스 스캔 과정에서 발생하는 비효율을 줄이기 - 인덱스 스캔 효율화 튜닝
Ex . 시력이 1.0 ~ 1.5인 김튜닝 이라는 학생을 찾을경우
이름과 시력 순으로 정렬 했다면 소량만 스캔하면 되는데 , 시력과 이름 순으로 정렬했다면
많은 양을 스캔 해야한다
2 ) 테이블 액세스 횟수 줄이기 - 랜덤 액세스 최소화 튜닝
인덱스 스캔후 테이블 레코드를 액세스 할 때 랜덤 I/O 방식을 사용 함
❗ 인덱스의 범위가 중요 하며 , 컬럼의 순서 또한 중요하다
1 - 3 인덱스 구조
DB에서 인덱스 없이 데이터를 검색하려면 테이블에 처음 ~ 끝 까지 모두 읽어야한다
그러나 인덱스를 이용 하면 일부만 읽고 멈출수 있다
즉 범위 스캔이 가능하다 , 가능한 이유는 인덱스가 정렬되어 있기 때문이다

ROWID는 한 행 고유의 물리적 주소 (실제 저장위치)이다.
오브젝트 번호 , 상대 파일 번호 , 블록번호 , 데이터 번호 이렇게 있다
- 오브젝트 번호 : 해당 데이터가 속하는 오브젝트 번호
- 상대파일 번호 : 데이터가 저장된 DataFile 의 번호 (TableSpace는 보통 여러개의 DataFile로 구성)
- 블록번호 : DataFile 안의 어느 블록인지를 의미함
- 데이터 번호 : 블록에서 데이터의 위치 (Data Directory Slot)
간략히 설명 하면 ROWID = 데이터 블록주소 + 로우 번호
- 데이터 블록주소 = 데이터 파일번호 + 블록번호
- 블록 번호 : 데이터 파일 내에서 부여한 상대적 순번
- 로우번호 : 블록 내의 순번
DBMS 는 일반적으로 B Tree 인덱스를 사용 하는데
고객 테이블에 고객명 컬럼 기준으로 만든 B Tree 인덱스 구조다
나무 (Tree)를 거꾸로 뒤집은 모양이어서 뿌리 (Root)가 위쪽에 있고 , 가지 (Branch)를 거쳐 맨 아래에
잎사귀 (Leaf)가 있다.
✔ Linked List로 연결되어있어 오름차순 내림차순 둘도 읽기가 가능하다
B Tree 에 'B'는 Balanced라는 약자인데
어떤 값으로 탐색하더라도 인덱스 루트에서 리프 블록에 도달하기까지 읽는 블록수가 같음을 뜻함
❗ 루트로부터 모든 리프블록 까지의 높이는 항상 같다.
수직적 탐색 : 인덱스 스캔 시작지점을 찾는 과정
수평적 탐색 : 데이터를 찾는 과정
인덱스 컬럼이 두개 이상일 때에는 컬럼의 순서가 중요하다.
화살표 길이(수평적 탐색의 범위)가 짧은 것이 성능면에서 좋다.
즉, 불필요한 많은 값을 거를 수 있는 인덱스가 먼저 오는 것이 좋다.
2️⃣ 인덱스 기본 사용법
1 - 1 인덱스를 Range Scan 할수 없는 이유
▶ 어떤 때에 인덱스를 사용 할수 없지 ?
인덱스 컬럼을 가공하면 인덱스를 정상적으로 사용 할수 없다.
왜 ?
인덱스 컬럼을 가공 하게되면 인덱스 스캔 시작점을 찾을수가 없기 때문
인덱스를 쓸 수 없는 경우
| 컬럼변형 |
| SubString |
| LIKE |
| OR |
| IN |
Index Range Scan 에서 Range는 범위를 의미하는데 인덱스에 일정 범위를 스캔한다는 뜻이다.
일정 범위를 스캔 하기 위해서는 시작과 끝이 있어야 한다.
1 - 2 인덱스를 이용한 소트 연산 생략
인덱스를 Range Scan 할 수 있는 이유 및 테이블과 달리 인덱스를 사용하는 이유는 데이터가 정렬되어 있기 때문.
정렬되어 있기 때문에 Range Scan이 가능하고 소트 연산 생략 효과도 부수적으로 얻게된다.

where 에 보면 장비번호와 변경일자가 모두 ' = ' 등치로 검색할때 PK 인덱스를 사용해 결과 집합은
변경 순번 순으로 출력이된다.
select *
from 상태변경이력
where 장비번호 = 'C'
and 변경일자 = '20180316'
order by 변경순번-- 실행 계획
----------------------------------------------------------
-- select Statement Optimizer = ALL_ROWS (Cost=86 Card = 81 Bytes = 5L)
-- TABLE ACCESS (BY INDEX ROWID ) of '상태변경이력' (TABLE) (Cost = 85...)
-- INDEX(RANGE SCAN) OF '상태변경이력_PK'(INDEX(INDEX)) (Cost = 3...)sort가 없다 .
왜 ? 인덱스를 이용해서 Sort 처리를 해서 Sort 없음
만약 정렬 연산을 생략할수 있게 인덱스가 구성되어 있지않다면 SORT ORDER BY 추가됨
Execution Plan
----------------------------------------------------------
-- select Statement Optimizer = ALL_ROWS (Cost=86 Card = 81 Bytes = 5L)
-- SORT (ORDER BY) (Cost = 86 Card = 81 Bytes = 5K)
-- TABLE ACCESS (BY INDEX ROWID ) of '상태변경이력' (TABLE) (Cost = 85...)
-- INDEX(RANGE SCAN) OF '상태변경이력_PK'(INDEX(INDEX)) (Cost = 3...)
1 - 3 ORDER BY 절에서의 컬럼 가공
select *
from 상태변경이력
where 장비번호 = 'C'
order by 변경일자 , 변경순번
수직적 탐색을 통해 장비번호가 'C'인 첫번째 레코드를 찾아 인덱스 리프 블록을 스캔하면 자동으로
변경일자 + 변경순번 순으로 정렬된다.
select *
from 상태변경이력
where 장비번호 = 'C'
order by 변경일자 || 변경순번 -- order by 절에서도 조심 , 인덱스 활용을 덜하게 된다이번에는 정렬 연산을 생략할수 없다
인덱스에는 가공하지 않은 상태로 값을 저장했는데 , 가공한 값 기준으로 정렬 해달라고 요청을 했기 때문
SELECT * FROM (
SELECT TO_CHAR(A.주문번호, 'FM000000') AS 주문번호, A.업체번호, A.주문금액
FROM 주문 A
WHERE A.주문일자 = :dt
AND A.주문번호 > NVL(:next_ord_no, 0)
ORDER BY 주문번호
)
WHERE ROWNUM <= 30;
-- 실행계획 (SORT ORDER BY 연산이 나타남)
-- SELECT STATEMENT
-- COUNT STOPKEY
-- VIEW
-- SORT ORDER BY STOPKEY
-- TABLE ACCESS BY INDEX ROWID
-- INDEX RANGE SCAN
-- ORDER BY문 앞에 ALIAS를 붙혀줌
SELECT * FROM (
SELECT TO_CHAR(A.주문번호, 'FM000000') AS 주문번호, A.업체번호, A.주문금액
FROM 주문 A
WHERE A.주문일자 = :dt
AND A.주문번호 > NVL(:next_ord_no, 0)
ORDER BY A.주문번호
)
WHERE ROWNUM <= 30;
-- 실행계획 (SORT ORDER BY 연산 생략)
-- SELECT STATEMENT
-- COUNT STOPKEY
-- VIEW
-- TABLE ACCESS BY INDEX ROWID
-- INDEX RANGE SCAN
1 - 4 SELECT -LIST 에서 컬럼가공
인덱스를 장비번호 + 변경일자 + 변경순번 순으로 구성하면
변경순번 최소 값을 구할 때도 옵티마이저는 정렬 연산을 따로 수행하지 않는다.
수직적 탐색을 통해 조건을 만족하는 가장 왼쪽 지점으로 내려가서 첫 번째 읽는 레코드가 바로 최소값
최대값을 찾을 때는 오른쪽으로 내려가는 점만 최소값과 다르다.
SELECT MIN(변경순번)
FROM 상태변경이력
WHERE 장비번호 = 'C'
and 변경일자 = '20180316'
-- 실행계획
-- STATEMENT
-- SORT AGGREGATE
-- INDEX RANGE SCAN
SELECT MAX(변경순번)
from 상태변경이력
where 장비번호 = 'C'
and 변경일자 = '20180316'
-- 실행계획
-- STATEMENT
-- SORT AGGREGATE
-- FIRST ROW
-- INDEX RANGE SCAN
자동 형변환
SQL 성능을 모르는 개발자는 TO_CHAR, TO_DATE, TO_NUMBER 같은 형변환 함수를 의도적으로 생략한다.
함수를 생략하면 연산횟수가 줄어 성능이 더 좋지 않을까라고 생각하기 때문.
성능은 그런데서 결정되는 것이 아니라 블록 I/O를 줄일 수 있느냐 없느냐에서 결정된다.
형변환 함수를 생략한다고 연산 횟수가 주는 것이 아닌 옵티마이저가 자동으로 생성한다.
- 오라클에서 숫자형과 문자형이 만나면 숫자형이 이긴다
- 날짜형과 문자형이 만나면 날짜형이 이긴다
3️⃣ 인덱스 확장기능 사용법
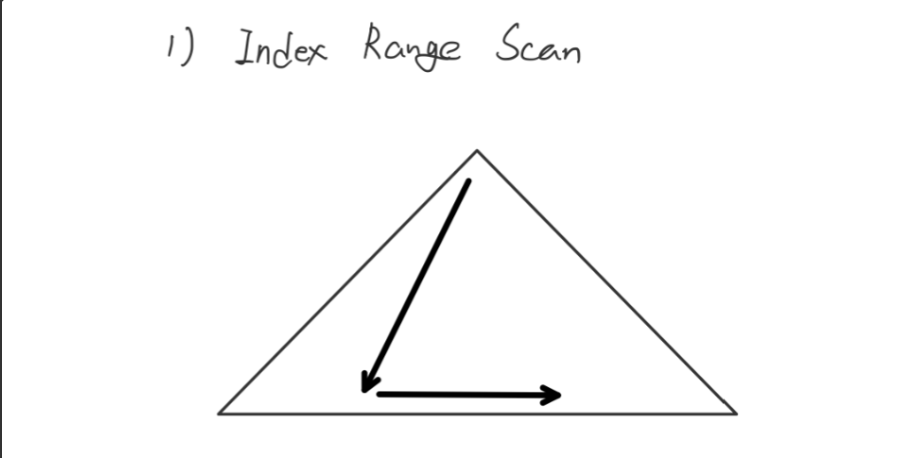
1 - 1 Index Range Scan
인덱스 루트에서 리프 블록까지 수직적으로 탐색후 '필욜한 범위'만 스캔
시작점과 끝점을 찾는방식 (가장 일반적이다)
1 - 2 Index Full Scan
수직적 탐색 없이 리프블록을 처음부터 끝까지 수평적으로 탐색하는 방식이다

1 - 3 Index Unique Scan
Unique 인덱스를 ' = ' 조건으로 탐색하는 경우에 작동한다.
PK 찾을 때 : 중복값이 없기 때문

1 - 4 Index Skip Scan
수평탐색이 너무 길 때 사용한다
같은 값의 데이터가 이어질 때 사용 가능하다

1 - 5 Index Range Scan Descending
뒤에서부터 탐색

1 - 6 Index Fast Full Scan (index_ffs)
Index Full Scan 보다 빠르다
논리적인 인덱스 트리 구조를 무시하고 인덱스 세그먼트 전체를 Multi block I / O 방식으로 스캔

'First > SQL 튜닝' 카테고리의 다른 글
| 🔑 SQL 튜닝 - CH 4. 조인 튜닝 - 해시 조인 (0) | 2023.08.18 |
|---|---|
| 🔑 SQL 튜닝 - CH 4. 조인 튜닝 - 소트 머지 조인 (0) | 2023.08.18 |
| 🔑 SQL 튜닝 - CH 4. 조인 튜닝 - NL 조인 (0) | 2023.08.18 |
| 🔑 SQL 튜닝 - CH 3. 인덱스 튜닝 (0) | 2023.08.18 |
| 🔑SQL 튜닝 - CH 1. SQL 처리과정 & I / O (2) | 2023.08.16 |



